待续…
Java多线程基础篇1
1、什么是多线程
百度百科上的解释是:多线程,是指从软件或者硬件上实现多个线程并发执行的技术。具有多线程能力的计算机因有硬件支持而能够在同一时间执行多于一个线程,进而提升整体处理性能。
在JAVA中多线程的状态有6中,分别是New、Runnable、Blocked、Waiting、Timed waiting、Terminated。其中new这个很好理解,就是创建一个新的线程,改线程还没开始运行。如果线程启动,即调用start(),那么线程状态就进入runnable,需要特别注意的是,线程处于runnable有没有运行这取决于操作系统给线程提供运行时间(这就有可能会导致在高并发的情况下,数据不安全,当然这也有相对应的解决方案)。刚接触多线程那会儿最困惑的就是阻塞和等待,感觉这两个状态都差不多,事实上并非如此,这两个状态其实差别非常大。首先是阻塞,当一个线程视图获取一个内部的对象锁,而该所被其他线程持有,那么该线程就进入阻塞状态。而等待是等待另外一个线程通知调度器一个条件,它自己进入等待状态,不同的地方在于阻塞是一个临界条件,没拿到锁的线程进入等待状态,拿到锁的线程可能因为某种条件不符合,无法往下执行,需要等待某种条件成立,然后由其他线程激活,进入runnable状态,如果能够拿到锁,那么线程会从等待的地方继续往下执行。被终止的线程一般有多个原因:1、因为run方法正常退出而自然死亡。2、run方法没有做异常处理导致意外死亡。
参考Java核心技术 卷1 基础知识 第9版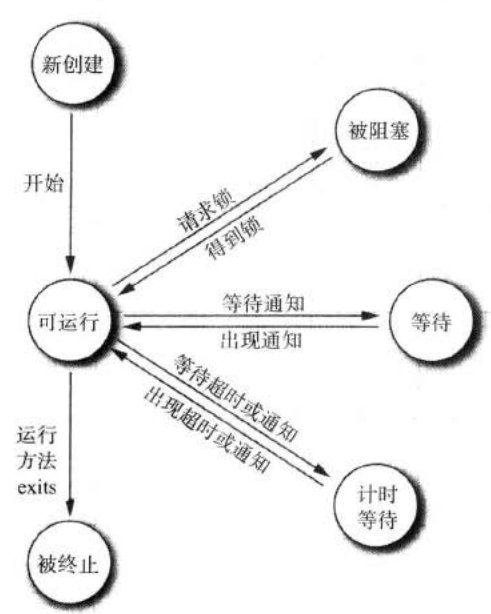
MySQL优化总结
接触MySQL已经有一段时间了,在这里对MySQL性能做个总结。关于MySQL的性能优化是一个很复杂的主题,受多方面的影响,如:硬件、网络、业务逻辑等。这里简单讨论scheme和索引
首先是scheme设计,最基础也是非常重要的环节。万丈高楼平地起,很大程度上,后续的优化都跟scheme设计有着千丝万缕的联系。
scheme的设计有一个很重要的元素就是选择合适的数据类型以及数据的长度。
数据长度直接影响数据页(innodb默认是16k)能容纳数据的数量,磁盘空间占用越大,所需要cpu、内存等硬件资源会越多,除此之外,随着磁盘占用空间越多,树的深度值可能会增加(注意,只是可能,因为数据增多,该叶子节点满了且其左右兄弟节点都满了,会导致分裂页,但是分裂页不一定会导致树深度变大,因为index page如果还没满的时候会导致分裂页,但是此时树的深度不变),树深度的增加一定会导致磁盘I/O次数增加。磁盘I/O相对来说是比较耗费时间的,特别是机械磁盘的随机I/O更加明显。对于固态硬盘同样适用,但是相对比机械磁盘吞吐量会好很多。如果是内存数据库则随机I/O影响很小,可以忽略。
在数据类型的选择还有另外一个因素,数据类型越简单越好,例如整数(类型与字符(char,varchar),整数的比较算法、排序算法比字符(char、varchar)简单,因此操作整数字符代价更低。
在scheme设计中,有时候为了提高查询性能,可能不会严格按照三大范式,设计中可能范式和反范式混合使用,具体说明时候该怎么使用需要了解这两种情况的优缺点。
范式化优点:
范式话通常意味着数据冗余越少,那么当需要更新操作的时候,需要变更的数据更少,B+TREE的维护成本就越低。
范式化的表通常越小,可以约容易缓存在内存。
范式化缺点:
需要关联操作,范式越高,关联的表就越多,表的关联查询本质就是多层循环嵌套查询。这不但代价昂贵,也可能使一些索引失效。
反范式优点:
不需要关联表,当数据比内存大时这可能比较关联快的多,因为这样避免了随机I/O。单独的表也能使用更有效的索引策略。
关于scheme的总结先写到这里,在前面的文章中我已近对部分不同数据类型的使用场景做了简单介绍,例如char与varchar、decimal…..
除了scheme设计,索引的优化也是很重要的,索引完全可以写成一本书,这里我只简单的介绍一下索引。首先要明确一个问题,那就是索引并不总是最好的工具。总的来说,只有当索引帮助存储引擎快速查找到记录带来的好处大于其他带来额外工作时,索引才是有效的。对于非常小的表,基本上全表扫描会比走索引性能好,但是在中大型的表中,好的索引就非常高效了。对于特大型的表索引可能不是最好的选择,这时候可以考虑表分区。
关于mysql innodb索引的问题其实可以转化成B+TREE的问题,因为MySQL innodb引擎就是使用B+TREE(关于B+TREE在之前的文章已经简单介绍,可以看前面写的文章),同时MySQL innodb对B+TREE进行优化,比如说分裂因子。索引的建立我觉得三星索引是一个很好的思想。什么是三星索引呢?三星索引的定义是这样的,如果与一个查询相关的索引是相邻的,或者至少相距足够靠近的话,那个这个索引就可以标记上第一颗星。如果索引行的顺序与查询语句的需求一致,则索引可以被标记第二颗星。如果索引行包含查询语句中的所有列,那么索引就可以标记上第三颗星。如果理解这段话呢?简单粗暴的说,第一颗星主要是来过滤到数据,减少索引片的厚度,索引相邻或者足够靠近过滤的数据就越多,当然,这也跟顺序有关,如果某个谓词是属于区间范围的,那么改索引往后的索引列都不会被使用。对于MySQL来说,有一个比较好的技巧的使用in(in列对应的值数量不多,且可以枚举)来更好的利用索引列。对于第二颗星,我认为主要还是为了排序的问题。如果排序的字段跟索引列的顺序一致,那么在获取数据的时候只需要在索引中读取,因为数据已经有序了。对于第三颗星,在三星索引的思想中是非常重要的一个。如果所有的字段都在索引里面,那么扫描索引后就不需要会表查询相关的数据。可以想象一下,一次随机I/O的时间是10ms,假设A表的索引记录100000,每条索引需要100字节,那么这个索引最少就需要100000100/1024,这是在理想的情况下,事实上还要考虑到磁盘碎片等各种利用率的情况如果所有的数据都能够在索引上获取,且在第一颗星中过滤只需要扫描100行索引,那么磁盘I/0所需要的时间就是10ms+100100kb/1024kb/40mb/s。如果需要回表操作,除了扫描索引外,还需要考虑到回表操作。由于回表操作是同步的,那么磁盘I/0所需要的时间10ms+100100kb/1024kb/40mb/s + 10ms100,初看这个时间不算特别夸张,但是在第一颗星过滤后的结果集如果非常大的时候,这可能是非常慢的。在实际问题中,有碰到鱼与熊掌不可兼得的情况,需要在第一颗星和第二颗星之间做选择,这种情况往往是因为第一颗星出现范围的谓词,且第二颗星排序的字段在谓词之后,一般情况下会选择第一颗星,而舍弃第二颗星,如果范围的谓词数量不大,且可以枚举,用in其实是一个很好的技巧(我曾经利用这个技巧把公司的网站从原来的35s降到1s)。对于选择第一颗星还是第二颗星,我觉得应该好好权很一下。当然,索引对查询带来了查询性能的提升,但是也提高了维护成本,相对来说现在的计算机硬件配置比以前好很多,索引维护的成本会比以前小很多,适当建立索引。
关于索引还有另外一个问题就是hint。事实上,MySQL现在的优化已经做的很好了,有时候也有可能因为统计误差太大导致选择不理想的执行计划,这种情况下,可以用hint提示。例如某些情况下,只需要在二级索引读取全部所需要的数据,这时候,可能优化器选择读取聚簇索引,这种情况下读取聚簇索引可能不是最好的选择,因为二级索引数据部分只有主键,这种结构就使二级索引比较小,另外所有的数据都只需要在二级索引里面读取,这样可以减少很多操作,比如不需要到在二级索引读取数据后获取主键然后再去聚簇索引找相关的数据块(注意是数据块,而不是具体定位到某一条数据的位置,因为读取时按照数据块来读取,然后在从内存通过二分法查找相关数据)。因此在磁盘I/O、内存、cpu等各个方面都很有优势,所以这种情况可以用hint提示。很多情况下MySQL给出的执行计划已经是最优的了,所以使用hint的时候需要清楚自己在做什么!
关于MySQL中sql优化特定的类型还有很多小技巧(待续)
TCP的超时与重传
TCP提供可靠的运输层。它使用的方法之一就是确认从另一端收到的数据。但数据和确认都有可能会丢失。 TCP通过在发送时设置一个定时器来解决这种问题。如果当定时器溢出时还没有收到确认,它就重传该数据。
拥塞避免算法和慢启动算法
拥塞避免算法和慢启动算法需要对每个连接维持两个变量:一个拥塞窗口cwnd和一个慢启动门限ssthresh。其中的工作原理如下:
1)对一个给定的连接,初始化cwnd为1个报文段,ssthresh为65535个字节
2)TCP输出不能超过cwnd和接收方的通告窗口的大小。拥塞避免是发送方使用的流量控制,而通告窗口是对接收方的流量控制。
拥塞避免是发送端感受到网络拥塞的估计,通告窗口是接收方在改连接上的可用缓存大小。
3)当拥塞发送时(超时或者受到重复确认),ssthresh被设置为当前窗口大小的一半即cwnd的一半)。如果是超时引起的拥塞,cwnd被设置成一个报文段。
4)当新的数据被对方确认,就增加cwnd,具体操作如下:
4.1)当cwnd<ssthresh,使用慢启动(每次受到确认,cwnd+1)
4.2)当cwnd>ssthresh,使用拥塞算法(每次受到确认,cwnd+=1/cwnd)
4.3)当cwnd=ssthresh,以上两种算法都可以
快速重传与快速恢复算法
TCP Reno算法
1)当收到第三个重复的ACK时,将ssthresh设置成当前拥塞窗口的一半(cwnd/2)。重传丢失报文段。设置cwnd为ssthresh加上3倍的报文段大小。
2)每次受到另外一个重复的ACK时,cwnd增加1个报文段大小并发送一个分组
3)当下一个确认新数据的ACK到达时,设置cwnd为ssthresh,进入拥塞避免阶段
这个算法存在问题,多个报文同时丢失的情况下会出现性能问题。因为会多次执行快速重传和快速恢复算法
TCP NEW Reno算法
当发送方这边收到3个重复,进入快速重传模式,开始重传丢失的包,如果只有一个包丢失,那么重传这个包后回来的ack就是发送方数据的ack。
否则就说明有多个包丢失,我们叫这个ACK为partial ACK。一旦发送方发现了partial ACK出现,那么发送方就继续推理出来有多个包丢失了,
于是继续重传丢失的包,知道不在出现partial ACK,整个过程结束。
B-TREE/B+TREE
B-TREE即平衡多路查找路(B->balance),一颗m阶的B-TREE有如下的特征:
1) 树中每个结点至多有m个孩子;
2) 除根结点和叶子结点外,其它每个结点至少有有ceil(m / 2)个孩子;
3) 若根结点不是叶子结点,则至少有2个孩子(特殊情况:没有孩子的根结点,即根结点为叶子结点,整棵树只有一个根节点);
4) 所有叶子结点都出现在同一层,叶子结点不包含任何关键字信息(可以看做是外部结点或查询失败的结点,实际上这些结点不存在,指向这些结点的指针都为null);
5) 每个非终端结点中包含有n个关键字信息: (n,P0,K1,P1,K2,P2,......,Kn,Pn)。其中:
a) Ki (i=1...n)为关键字,且关键字按顺序排序K(i-1)< Ki。
b) Pi为指向子树根的接点,且指针P(i-1)指向子树种所有结点的关键字均小于Ki,但都大于K(i-1)。
c) 关键字的个数n必须满足: ceil(m / 2)-1 <= n <= m-1。
B-TREE的查询操作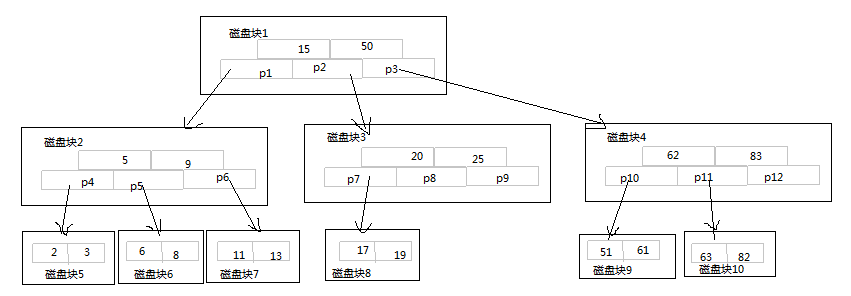
首先把磁盘块1导入到内存中,通过折半查找,找到P3指针(50<51)
通过P3指针找到磁盘块4,将磁盘块4导入内存中,通过折半查找P10指针(51<62)
通过P10指针找到磁盘块9,将磁盘块9导入内存中,通过值班查找找到51
至此,整个查找过程就结束了,这个过程一共进行了三次磁盘IO
B-TREE的添加操作
插入一个元素时,首先在B-TREE中是否存在,如果不存在,先判断叶子节点的空间是否足够,如果足够,就往叶子节点里面添加,如果不够,就需要分裂页操作。
分裂页将一半数量的关键字分裂到新的叶子节点,同时将中间节点更新到父节点中,这时候需要分两种情况,如果父节点还没满,就直接插入,如果父节点已经满,
需要分裂页,父节点中间节点更新到爷爷节点,整个过程以此类推。直到整棵树平衡。
B-TREE的删除操作
A、删除节点在叶子节点上
A.1)如果被删除关键字所在结点的原关键字个数n>=ceil(m/2),直接删除该节点的关键字。
A.2)如果被删除关键字所在结点的关键字个数n等于ceil(m/2)-1,那么需要看看兄弟节点
A.2.1.如果兄弟节点关键字>=ceil(m/2),采用覆盖操作,父节点覆盖删除节点,兄弟节点最值覆盖原来的父节点
A.2.2.如果兄弟节点关键字=ceil(m/2),需要把兄弟节点与父节点合并作为新节点,合并后可能导致父节点不符合B-TREE结构要求,
需要继续合并,直到B-TREE满足条件。
B、删除的节点不在叶子节点上,可以通过将左子书的最大关键字(右字数的最小节点)K-max覆盖到要删除的节点key-parent。
接下来问题相当于转成删除key-max节点的问题,步骤转向A
B+TREE是B-TREE的一种优化
一颗m阶的B+TREE和B-TREE异同点:
1、有n棵子树的节点包含n-1个关键字(此处有争议,部分教材是n-1个关键字,但是部分教材是n个关键字)
2、所有关键字以及值都放在叶子节点中(非叶子节点相当于索引)
B+TREE的添加操作分成三种情况
A)如果叶子节还没满,直接插入
B)如果叶子节点满,父节点还没满,拆分叶子节点,将中间节点放入父节点中
小于中间节点的放在父节点的左边,大于中间节点的放在父节点的右边
C)如果叶子节点满了,父节点也满了,拆分叶子节点,小于中间节点的放在左边
大于中间节点的放在右边,拆分父节点小于中间节点的放在左边大于中间节点的
放右边。中间节点放在上一层。以此类推。直到整颗树平衡。
B+TREE的删除操作
A)如果叶子节点高于填充因子,直接删除节点
B)如果叶子节点低于填充因子,且父节点高于填充因子,
需要合并兄弟节
更新父节点
C)如果叶子结点低于填充因子,且父节点低于填充因子,
需要合并兄弟节点
更新父节点
合并父节点以及更新对应的节点
OAuth2.0
OAuth(开放授权)是一个开放标准,允许用户授权第三方应用访问用户在其他平台存储的数据(前提是平台有授权),而不需要给第三方提供账号和密码。(简单的说就是一个验证、授权的过程)
应用场景:
第三方登录。例如网站A想接入Google、QQ、wechat等第三方的登录。那么需要怎么做呢?首先是A网站根据用户的选择(Google、QQ、wechat等)重定向到对应的第三方登录页面,通过用户授权。用户授权通过后网站A会获取到一个授权码(get方式),网站A带上授权码向第三方申请令牌(post方式),第三方通过验证后给网站返回令牌信息。网站A通过令牌信息可以调用第三方对应的接口,例如登录成功后获取用户信息。(OAuth2.0的应用场景其实有很多,比如单点登录,API调用等)
具体实现:
在OAuth2.0中,实现的方式有很多种,在这里我只写一种,即授权码模式。
授权码模式是功能最完整、流程最严密的授权模式。
+----------+
| Resource |
| Owner |
| |
+----------+
^
|
(B)
+----|-----+ Client Identifier +---------------+
| -+----(A)-- & Redirection URI ---->| |
| User- | | Authorization |
| Agent -+----(B)-- User authenticates --->| Server |
| | | |
| -+----(C)-- Authorization Code ---<| |
+-|----|---+ +---------------+
| | ^ v
(A) (C) | |
| | | |
^ v | |
+---------+ | |
| |>---(D)-- Authorization Code ---------' |
| Client | & Redirection URI |
| | |
| |<---(E)----- Access Token -------------------'
+---------+ (w/ Optional Refresh Token)
Figure 3: Authorization Code Flow
(A)用户访问客户端,客户端将用户导向认证服务器(Authorization Server)
(B)授权服务器认证资源所有者,并确定资源所有者授予或拒绝客户端的访问请求。
(C)若资源所有者授予访问权限服务器将用户代理重定向回客户端之前提供的重定向URI(在请求中或之前)。
重定向URI包括一个授权代码(这是一个get请求的过程,授权码是一个临时令牌用于获取后期的token)
(D)客户端拿到临时临牌后,授权服务器请求access token,这个过程用post请求,因为get请求会被记录到系统日志
(E)授权服务器验证客户端,验证授权代码,并确保重定向URI收到的匹配用于重定向客户端的URI 步骤(C)。
如果有效则授权服务器回应访问令牌和可选的刷新令牌
拿到access token后,就可以访问授权服务器提供的api了。
本文参考OAuth2.0官网,后期附上整个过程的数据包分析以及用asp.net mvc实现的代码。
OAuth2.0官网 https://tools.ietf.org/html/rfc6749
从认证到授权的整个过程的英文文档如下
Note: The lines illustrating steps (A), (B), and (C) are broken into
two parts as they pass through the user-agent.
The flow illustrated in Figure 3 includes the following steps:
(A) The client initiates the flow by directing the resource owner's
user-agent to the authorization endpoint. The client includes
its client identifier, requested scope, local state, and a
redirection URI to which the authorization server will send the
user-agent back once access is granted (or denied).
(B) The authorization server authenticates the resource owner (via
the user-agent) and establishes whether the resource owner
grants or denies the client's access request.
(C) Assuming the resource owner grants access, the authorization
server redirects the user-agent back to the client using the
redirection URI provided earlier (in the request or during
client registration). The redirection URI includes an
authorization code and any local state provided by the client
earlier.
(D) The client requests an access token from the authorization
server's token endpoint by including the authorization code
received in the previous step. When making the request, the
client authenticates with the authorization server. The client
includes the redirection URI used to obtain the authorization
code for verification.
(E) The authorization server authenticates the client, validates the
authorization code, and ensures that the redirection URI
received matches the URI used to redirect the client in
step (C). If valid, the authorization server responds back with
an access token and, optionally, a refresh token.
MySQL innodb 索引原理
innodb存储引擎支持B+tree索引,哈希索引(根据表的使用情况自动为表生成哈希索引,不能人为干预)。B+tree是根据key快速找到叶子页,因为B+tree是按照顺序存储的,每个叶子也到根的距离相同,从整体的来说,是对B-tree的一个优化,降低了树的深度,减少了磁盘IO的次数。(一般磁盘每s的io次数是100次)
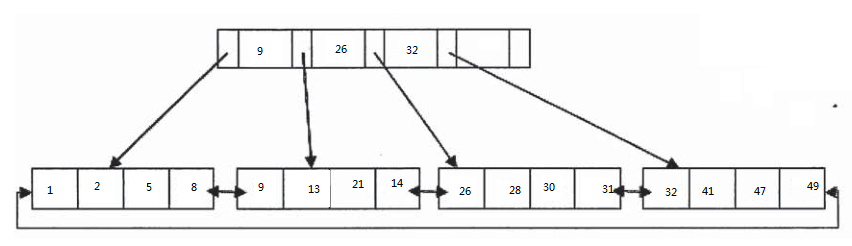
innodb是如何查找数据的呢。innod的存储结构决定了innodb需要从跟节点开始查找,节点中的指针指向下一个节点,直到最后的叶子页。叶子节点的指针指向数据。所以这些数据key就是有序的。曾看过有关.net ef框架的性能测试,测试者通过主键查找数据,来测试EF的性能。我认为这个测试的结果意义不太,因为数据库主键是一个非常特别的key,即使需要通过主键排序等其他操作,问题也不是特别大,B+tree的存储特点让主键占据了非常大的优势。不过需要主要的是,如果主键设置不合理,对于整张表的性能影响也是非常大的。
在innodb中,一般情况下二级索引性能比主键会差一点,但这规律不一定适合索引覆盖。首先二级索引处理我们认为添加的列之外,还会有默认的主键列,除非能够在二级索引列里面找到我们想要的数据,例如:我们在建立的覆盖索引能够获取到我们全部的数据,那么我们就可以直接从覆盖索引里面的数据然后返回客户端,不然每次都是通过二级索引得到对应的主键,然后通过主键再重复上述主键查找数据的过程。
根据设计,B+tree需要随机磁盘访问才能定位到叶子页,所以随机访问是不可避免的。然而,如果叶子页在物理分布上是顺序且紧密的,那么查询性能会跟好,否则对于范围查询,索引覆盖扫描等操作来说,速度可能会见底很多倍。对于索引覆盖扫描这一点更加明显。
innodb数据从磁盘到内存这个过程是怎么样的。这个问题曾经也困扰了我很久。其实B+tree不能通过找到key来找到特定行在磁盘的具体位置,在查找的时候只能通过key找到key所在的也,然后把页读入内存中,在内存中找到相关的记录。一般磁盘的扇区是4k,MySQL的页默认值是16k,这对频繁读写是有好处的。
MySQL切换主库
在MySQL复制中有很多种结构,目前只介绍两种(主主,主从),事实上MySQL还有其他拓扑,例如金字塔,主库-分发主库-备库等等。这些拓扑在解决带宽瓶颈表现也非常优秀,这些拓扑结构先略过。今天先讨论一些关于主主拓扑结构和主从拓扑结构切换主库的方式。
一般来说,切换主库的思路就是
先停止主库的写入
备库赶上主库
选择一台备库作为主库
将备库的写操作指向新主库,开启新主库
主从拓扑(计划内切换主库)
停止当前主库上的所有写操作,如果可以,最好能够将所有客户端程序关闭。如果使用虚拟ip,直接关闭所有客户端连接。
通过flush tables with read lock在主库上停止所有的活跃写入,这一步也是可选的。也可以在主库上设置read_only选项。这时候应该禁止向即将被替换的主库写入数据。因为一旦它不是主库,写入就意味着数据丢失。
选择一个备库作为新的主库,并确保他已经完全跟上主库
检查新主库和就主库的数据一致性
在新主库上执行stop slave
在新主库上执行change master to master_host='',然后在执行reset slave;断开与老主库的连接,并丢弃master.info的记录信息。
执行show master status记录新主库的二进制日志位置
确保在其他备库已经刚上了(如果没有赶上,后期操作比较麻烦,需要计算新主库的偏移量)
关闭旧数据库
在MySQL5.1以上的版本中,如果需要,激活新主库上时间。
将客户端连接到新主库
在备库上改变主库的ip。change master to
主从拓扑(计划外切换主库)
找到备库数据最新的服务器。检查每台备库上show slave status命令的输出,选择其中master_log_file/read_master_log_pos的值最新的那个。
让所有备库执行完成所有其从崩溃前的旧主库那获得的中继日志。如果在未完成前修改备库的主库,它会抛弃剩下的日志事件,从而无法获知改备库在上面地方停止。
在新主库上执行stop slave
在新主库上执行change master to master_host='',然后在执行reset slave;断开与老主库的连接,并丢弃master.info的记录信息。
执行show master status记录新主库的二进制日志位置
比较每台备库和新主库上的master_log_file/read_master_log_pos的值。
在MySQL5.1以上的版本中,如果需要,激活新主库上时间。
将客户端连接到新主库
在备库上改变主库的ip。change master to
主主拓扑结构
停止主动服务器上的所有写入
通过flush tables with read lock在主库上停止所有的活跃写入,否则需要kill所有客户端的连接。
在主动服务器上执行show master status,记录二进制偏移量。
使用主动服务器上的二进制日志坐标在移动服务器上执行select master_pos_wait().改语句将阻塞住,知道复制跟上主动服务器。
在被动服务器上执行set global read_only=0,这样就变成主动服务器
修改应用程序的配置,使其写入到新的主动服务器中。
通过以上的对比,可以看出主主结构在切换主库会比主备拓扑结构切换主库方便。因此如果是需要高可用的场景,选择主主拓扑主-被结构(配合keepalive,haproxy or lvs)。如果是需要实现读写分离来提升系统的性能,那么主备拓扑结构是一个很不错的选择(前提是写不是整个架构的瓶颈,因为写容量不能通过复制在提升)
MySQL主主拓扑结构
主主复制有两台服务器,每一个都被配置成对方的主库和备库。主主拓扑结构有两种配置,一种是主主拓扑结构中的主-主模式。这种模式下,两台服务器都可以写入。那么最大的问题就是如何防止冲突的问题,另外在两台机器上根据不同的顺序更新,可能会导致数据不同步。例如在第一台主库上:
update tableA set col=col+1;
在第二台主库上:
update tableA set col=col*2;
在这种情况下,第一台实际在数据库执行的是
update tableA set col=col+1;
update tableA set col=col*2;
第一台得到的结果是4,在第二台主机上执行的是
update tableA set col=col*2;
update tableA set col=col+1;
那么得到的结果就是3。这种拓扑结构导致了两个库的数据不一致。如果清除自己在做什么,那么可以考虑这种结构,否则,尽量别用,因为有些疑难杂症很难处理好。
在主主拓扑结构中还有另外一种模式,主-被拓扑模式,这种结构能够很好的避免主主结构中主-主模式的一些问题。这种结构跟主-主结构的区别在于其中被动服务器只读,如图所示。由于主主结构主-被模式配置都是对称的(其中,把对方都设置成备库的配置在往后的故障转移和故障恢复起到非常重要的作用),所以在这种特殊的配置中,主-被模式反复切换模式很方便(这些操作相对于主从来说,会少了很多工作量,后续会对主从、主主拓扑结构的主被模式切换主库做个对比),这对系统的故障转移和故障恢复很容易。对于整个系统实现高可用也是非常方便且有效的(可能会配合其他负载均衡如[lvs、haproxy]+keepalive或虚拟IP等相关技术一起使用,具体方案视情况而定)。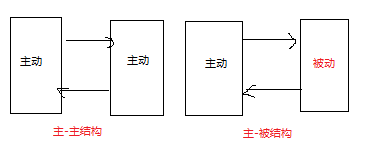
vrrp协议
vrrp简述:
vrrp协议即虚拟路由冗余协议,通过多台路由设备联合组成一台虚拟的路由设备,当主机的下一跳路由出现故障时,自动选举备份路由,把业务切换到备份路由器。
vrrp工作过程(内容来做百度百科)
路由器开启VRRP功能后,会根据优先级确定自己在备份组中的角色。优先级高的路由器成为主用路由器,优先级低的成为备用路由器。主用路由器定期发送VRRP通告报文,通知备份组内的其他路由器自己工作正常;备用路由器则启动定时器等待通告报文的到来。
VRRP在不同的主用抢占方式下,主用角色的替换方式不同:
在抢占方式下,当主用路由器收到VRRP通告报文后,会将自己的优先级与通告报文中的优先级进行比较。如果大于通告报文中的优先级,则成为主用路由器;否则将保持备用状态。
在非抢占方式下,只要主用路由器没有出现故障,备份组中的路由器始终保持主用或备用状态,备份组中的路由器即使随后被配置了更高的优先级也不会成为主用路由器。
如果备用路由器的定时器超时后仍未收到主用路由器发送来的VRRP通告报文,则认为主用路由器已经无法正常工作,此时备用路由器会认为自己是主用路由器,并对外发送VRRP通告报文。备份组内的路由器根据优先级选举出主用路由器,承担报文的转发功能。
