innodb存储引擎支持B+tree索引,哈希索引(根据表的使用情况自动为表生成哈希索引,不能人为干预)。B+tree是根据key快速找到叶子页,因为B+tree是按照顺序存储的,每个叶子也到根的距离相同,从整体的来说,是对B-tree的一个优化,降低了树的深度,减少了磁盘IO的次数。(一般磁盘每s的io次数是100次)
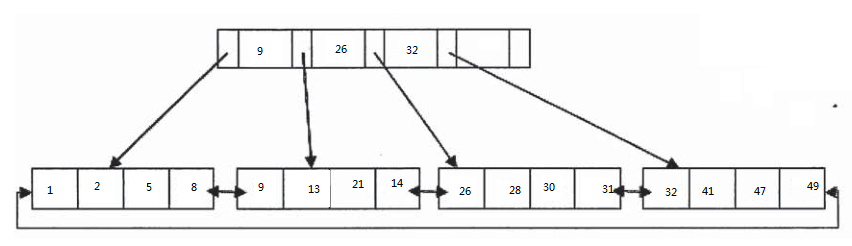
innodb是如何查找数据的呢。innod的存储结构决定了innodb需要从跟节点开始查找,节点中的指针指向下一个节点,直到最后的叶子页。叶子节点的指针指向数据。所以这些数据key就是有序的。曾看过有关.net ef框架的性能测试,测试者通过主键查找数据,来测试EF的性能。我认为这个测试的结果意义不太,因为数据库主键是一个非常特别的key,即使需要通过主键排序等其他操作,问题也不是特别大,B+tree的存储特点让主键占据了非常大的优势。不过需要主要的是,如果主键设置不合理,对于整张表的性能影响也是非常大的。
在innodb中,一般情况下二级索引性能比主键会差一点,但这规律不一定适合索引覆盖。首先二级索引处理我们认为添加的列之外,还会有默认的主键列,除非能够在二级索引列里面找到我们想要的数据,例如:我们在建立的覆盖索引能够获取到我们全部的数据,那么我们就可以直接从覆盖索引里面的数据然后返回客户端,不然每次都是通过二级索引得到对应的主键,然后通过主键再重复上述主键查找数据的过程。
根据设计,B+tree需要随机磁盘访问才能定位到叶子页,所以随机访问是不可避免的。然而,如果叶子页在物理分布上是顺序且紧密的,那么查询性能会跟好,否则对于范围查询,索引覆盖扫描等操作来说,速度可能会见底很多倍。对于索引覆盖扫描这一点更加明显。
innodb数据从磁盘到内存这个过程是怎么样的。这个问题曾经也困扰了我很久。其实B+tree不能通过找到key来找到特定行在磁盘的具体位置,在查找的时候只能通过key找到key所在的也,然后把页读入内存中,在内存中找到相关的记录。一般磁盘的扇区是4k,MySQL的页默认值是16k,这对频繁读写是有好处的。
