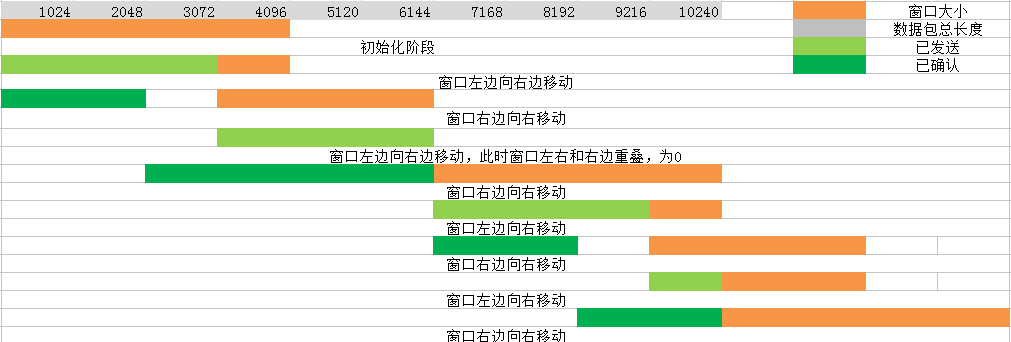
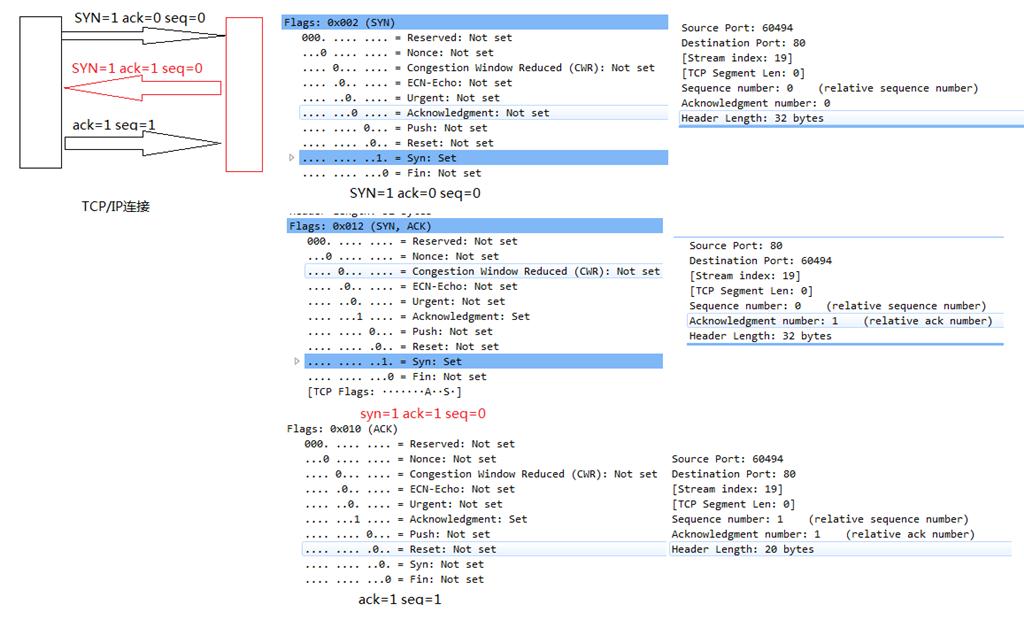
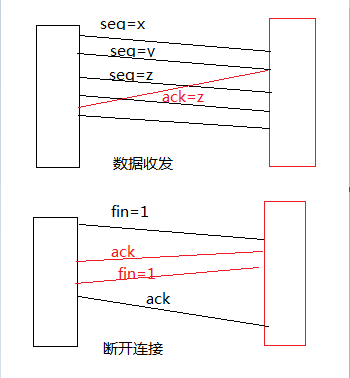
从连接到断开整个过程中,数据交换是我觉得最复杂的一个模块。在这里我简单描述一下在局域网中成块数据块流收发的过程。
首先,发送方从缓存里面读取数据。并不是一收到数据就马上发送,而是根据恰当的时间对数据进行发送(长度优先和时间优先)。开始发送数据时,因为在连接的过程中就知道接收方的窗口大小,所以发送方会一次发送一个或多个数据包,但是发送的数据不会超过窗口的大小(发送方可以自行计算)。接收方一接收到数据后,也不是马上发送确认包,而是会等待一段时间,如果有数据,那么数据包和确认包将一起发送过去。否则只发送确认包。收到确认包后,接收方的窗口右边往右移动。数据收发中,不断重复这个过程,直到数据收发结束。从整个收发的过程中看出,增大接收方的窗口大小一定程度上能够提高TCP的吞吐量,从而提高整个数据收发的效率。